Reproduction of LeGrad
An Explainability Method for Vision Transformers via Feature Formation Sensitivity
Links
- 🔗 GitHub Repository: Shaun-Z/LeGrad
- 📄 Original Paper: LeGrad
- 🌟 Original Implementation: WalBouss/LeGrad
Overview
I recently implemented an enhanced version of LeGrad, an explainability method for Vision Transformers that reveals how these models form features through gradient-based analysis. My implementation adds batch computation support, significantly improving efficiency when analyzing multiple images.
LeGrad helps us peek inside the “black box” of Vision Transformers by visualizing attention patterns and feature formation across different layers, making AI decisions more interpretable and trustworthy.
What is LeGrad?
LeGrad (a Layerwise Explainability method that utilizes the Gradient with respect to attention maps) is an explainability method introduced at ICCV 2025 that analyzes Vision Transformers by examining feature formation sensitivity. Unlike traditional attention visualization methods, LeGrad provides deeper insights into how features are progressively built throughout the network layers.
Key Innovation: My implementation extends the original work to support batch processing, enabling efficient analysis of multiple images simultaneously.
Features
✨ Batch Computation Support - Process multiple images in parallel for improved efficiency
🎨 Layer-wise Visualization - Track feature formation across transformer layers
🔧 OpenCLIP Integration - Built on the robust OpenCLIP framework
📊 Attention Heatmaps - Generate intuitive visualizations of model focus
📝 MIT Licensed - Open source and free to use
Results
Single Image Analysis
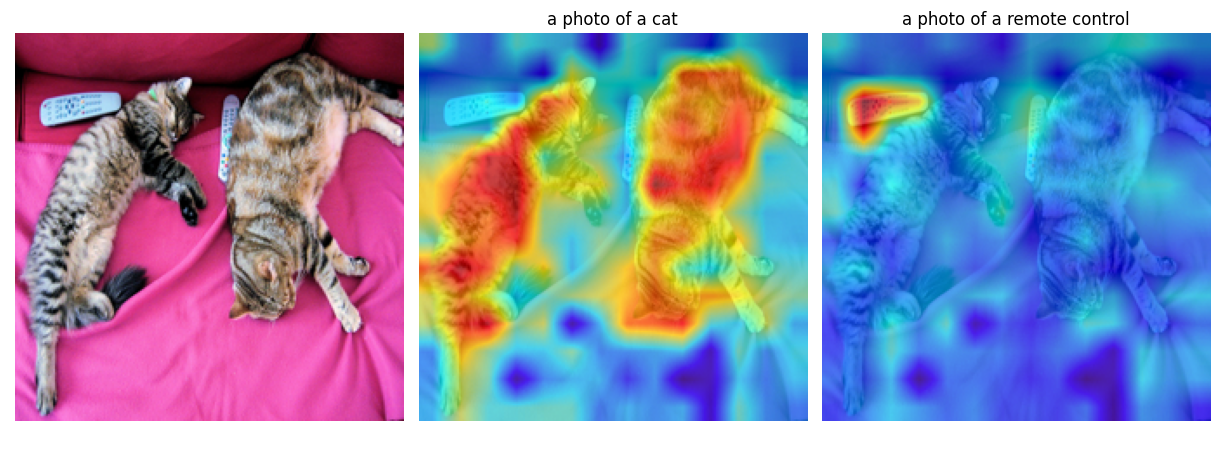
Batch Processing

Layer-wise Visualization


These visualizations demonstrate how the Vision Transformer progressively focuses on relevant features, with earlier layers capturing low-level patterns and deeper layers refining semantic understanding.
Technical Implementation
The implementation leverages gradient-based attribution to compute feature importance scores across transformer layers. The batch support enhancement required careful optimization of:
- Memory-efficient gradient computation
- Parallel processing of attention maps
- Vectorized operations for heatmap generation
Built with Python and integrated with OpenCLIP for state-of-the-art vision transformer models.
Quick Start
# Example usage from the repository
python examples/openclip_cat_remote.py # Single image analysis
python examples/openclip_coco_batch.py # Batch processing
Check out the GitHub repository for detailed documentation and examples.
Why This Matters
Explainability in AI is crucial for:
- Trust & Safety - Understanding model decisions in critical applications
- Debugging - Identifying failure modes and biases
- Research - Gaining insights into model behavior and architecture design
- Compliance - Meeting regulatory requirements for AI transparency
Vision Transformers have revolutionized computer vision, but their complex attention mechanisms can be opaque. LeGrad provides a powerful tool for making these models more interpretable.
References
Based on the research paper:
LeGrad: An Explainability Method for Vision Transformers via Feature Formation Sensitivity
@inproceedings{bousselham2025legrad,
title={Legrad: An explainability method for vision transformers via feature formation sensitivity},
author={Bousselham, Walid and Boggust, Angie and Chaybouti, Sofian and Strobelt, Hendrik and Kuehne, Hilde},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={20336--20345},
year={2025}
}
Feel free to explore the code, try it with your own images, and contribute to making Vision Transformers more interpretable!